Evaluation Concepts
High-quality evaluations are key to creating, refining, and validating AI applications. In LangSmith, you’ll find the tools you need to structure these evaluations so that you can iterate efficiently, confirm that changes to your application improve performance, and ensure that your system continues to work as intended.
This guide explores LangSmith’s evaluation framework and core concepts, including:
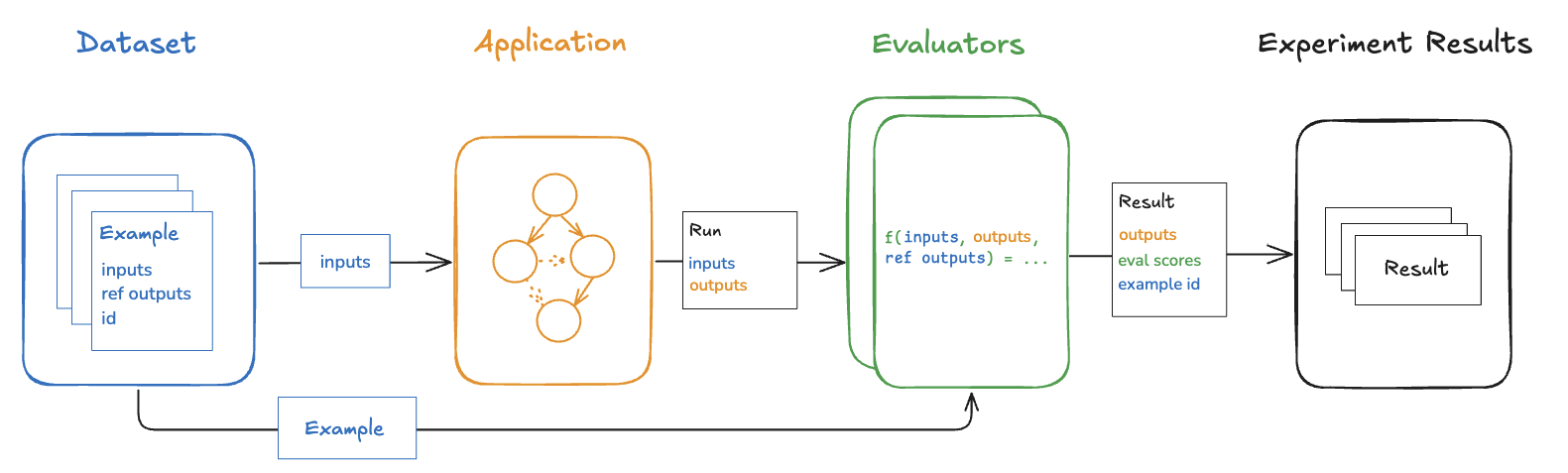
- Datasets, which hold test examples for your application’s inputs (and, optionally, reference outputs).
- Evaluators, which assess how well your application’s outputs align with the desired criteria.
Datasets�
A dataset is a curated set of test examples. Each example can include inputs (the data you feed into your application), optional reference outputs (the “gold-standard” or target answers), and any metadata you find helpful.
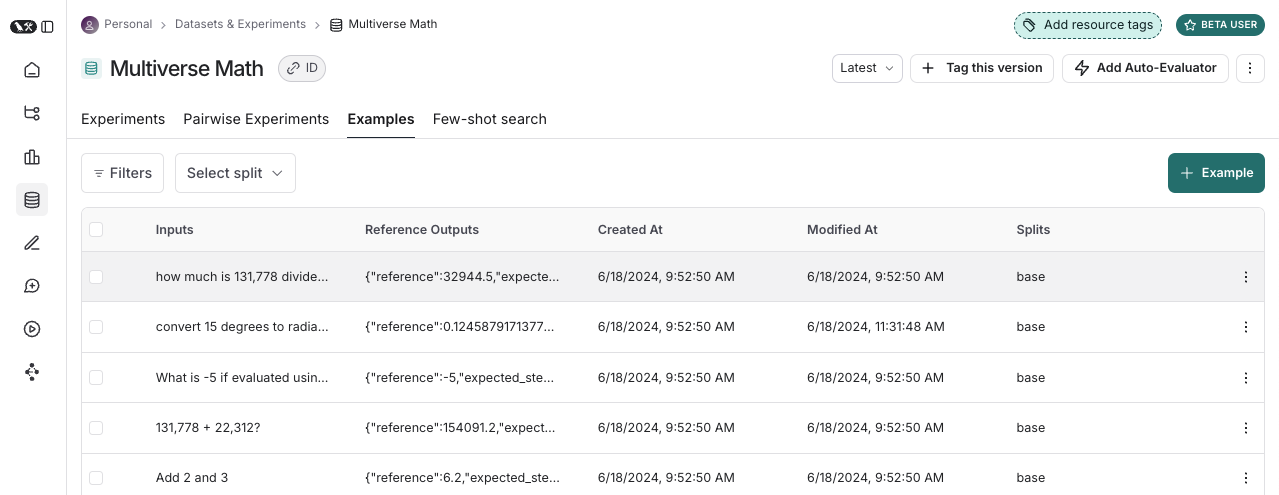
Examples
Each example corresponds to a single test case. In most scenarios, an example has three components. First, it has one or more inputs provided as a dictionary. Next, there can be reference outputs (if you have a known response to compare against). Finally, you can attach metadata in a dictionary format to store notes or tags, making it easy to slice, filter, or categorize examples later.
Dataset Curation
When constructing datasets, there are a few common ways to ensure they match real-world use cases:
- Manually Curated Examples. This includes handpicking representative tasks and responses that illustrate normal usage and tricky edge cases. Even a small selection of 10 to 20 examples can yield substantial insights.
- Historical Traces. If your system is already in production, gather actual production runs, including examples flagged as problematic by users or system logs. Filtering based on complaints, repeating questions, anomaly detection, or LLM-as-judge feedback can provide a realistic snapshot of real-world usage.
- Synthetic Generation. A language model can help you automatically generate new test scenarios, which is especially efficient if you have a baseline set of high-quality examples to guide it.
Splits
To organize your dataset, LangSmith allows you to create one or more splits. Splits let you isolate subsets of data for targeted experiments. For instance, you might keep a small “dev” split for rapid iterating and a larger “test” split for comprehensive performance checks. In a retrieval-augmented generation (RAG) system, for example, you could divide data between factual vs. opinion-oriented queries.
Read more about creating and managing splits here.
Versions
Every time your dataset changes—if you add new examples, edit existing ones, or remove any entries—LangSmith creates a new version automatically. This ensures you can always revert or revisit earlier states if needed. You can label versions with meaningful tags to mark particular stages of your dataset, and you can run evaluations on any specific version for consistent comparisons over time.
Further details on dataset versioning are provided here.
Evaluators
Evaluators assign metrics or grades to your application’s outputs, making it easier to see how well those outputs meet your desired standards.
Techniques
Below are common strategies for evaluating outputs from large language models (LLMs):
- Human Review. You and your team can manually assess outputs for correctness and user satisfaction. Use LangSmith Annotation Queues for a structured workflow, including permissions, guidelines, and progress tracking.
- Heuristic Checking. Basic rule-based evaluators help detect issues such as empty responses, excessive length, or missing essential keywords.
- LLM-as-Judge. A language model can serve as the evaluator, typically via a dedicated prompt that checks correctness, helpfulness, or style. This method works with or without reference outputs.
- Pairwise Comparisons. When deciding between two application versions, it can be simpler to ask, “Which output is better?” rather than to assign absolute scores, especially in creative tasks like summarization.
Defining Evaluators
You can use LangSmith’s built-in evaluators or build your own in Python or TypeScript. You can then run these evaluators through the LangSmith SDK, the Prompt Playground (inside LangSmith), or in any automation pipeline you set up.
Evaluator Inputs
An evaluator has access to both the example (input data and optional reference outputs) and the run (the live output from your application). Because each run often includes details like the final answer or any intermediate steps (e.g., tool calls), evaluators can capture nuanced performance metrics.
Evaluator Outputs
Evaluators usually produce responses in the form of dictionaries (or lists of dictionaries). Each entry typically contains:
- A “key” or name for the metric.
- A “score” or “value” (numeric or categorical).
- An optional “comment” to explain how or why the score was assigned.
Experiment
Any time you pass your dataset’s inputs into your application—whether you’re testing a new prompt, a new model, or a new system configuration—you’re effectively starting an experiment. LangSmith keeps track of these experiments so you can compare differences in outputs side by side. This makes it easier to catch regressions, confirm improvements, and refine your system step by step.
Annotation Queues
Annotation queues power the process of collecting real user feedback. They let you direct runs into a pipeline where human annotators can label, grade, or comment on outputs. You might label every run, or just a sample if your traffic is large. Over time, these labels can form their own dataset for further offline evaluation. Annotation queues are thus a key tool for harnessing human feedback in a consistent, transparent manner.
To learn more about annotation queues, visit here
Offline Evaluation
Offline evaluation focuses on a static dataset rather than live user queries. It’s an excellent practice to verify changes before deployment or measure how your system handles historical use cases.
Benchmarking
Benchmarking compares your system’s outputs to some fixed standard. For question-answering tasks, you might compare the model’s responses against reference answers and compute similarity. Or you could use an LLM-as-judge approach. Typically, large-scale benchmarking is reserved for major system updates, since it requires maintaining extensive curated datasets.
Unit Tests
Classic “unit tests” can still be applied to LLMs. You can write logic-based checks looking for empty strings, invalid JSON, or other fundamental errors. These tests can run during your continuous integration (CI) process, catching critical issues anytime you change prompts, models, or other code.
Regression Tests
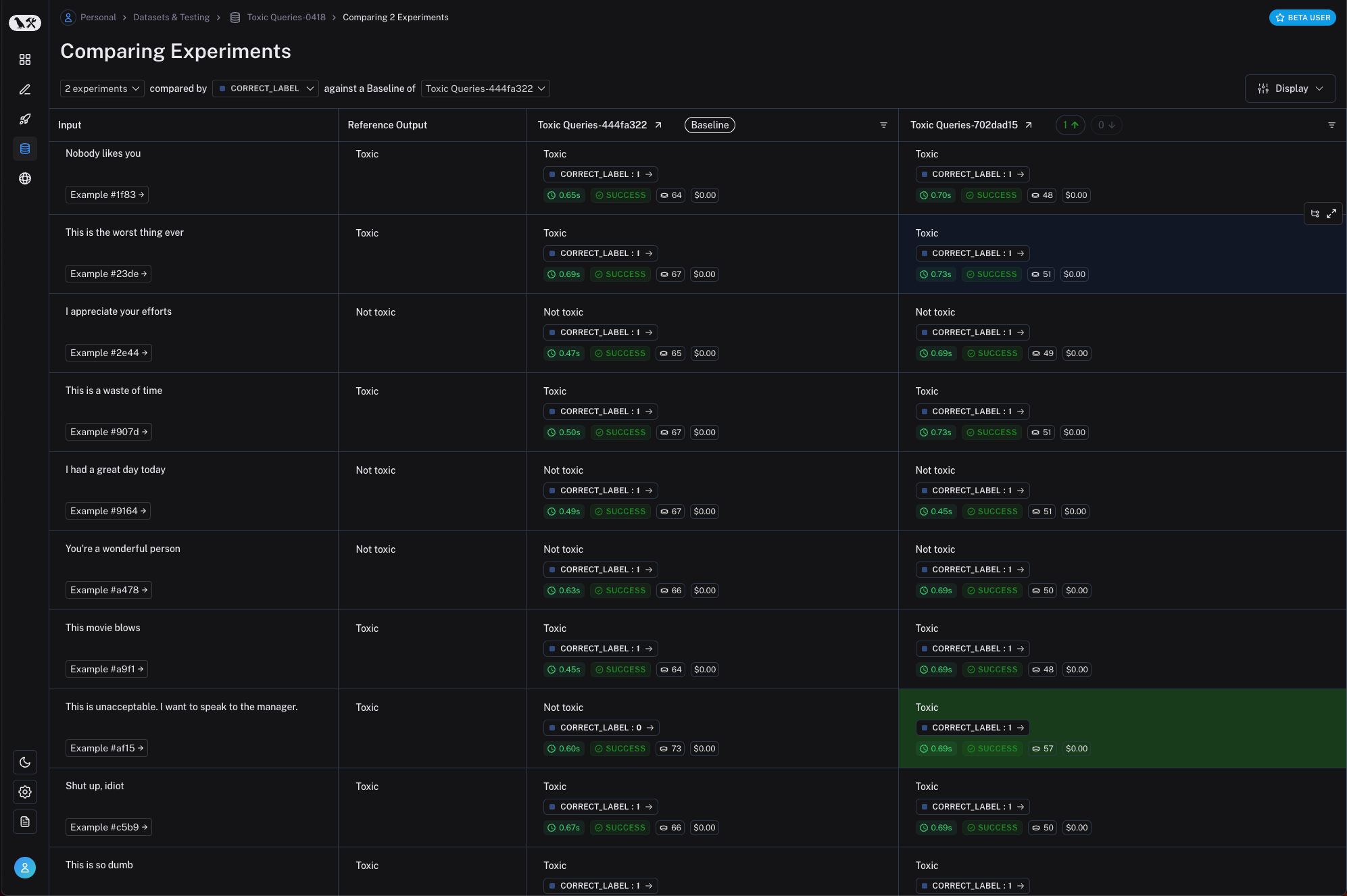
Regression tests help ensure that today’s improvements don’t break yesterday’s successes. After a prompt tweak or model update, you can re-run the same dataset and directly compare new results against old ones. LangSmith’s dashboard highlights any degradations in red and improvements in green, making it easy to see how the changes affect overall performance.
Illustration: Regression view highlights newly broken examples in red, improvements in green.
Backtesting
Backtesting replays past production runs against your updated system. By comparing new outputs to what you served previously, you gain a real-world perspective on whether the upgrade will solve user pain points or potentially introduce new problems—all without impacting live users.
Pairwise Evaluation
Sometimes it’s more natural to decide which output is better rather than relying on absolute scoring. With offline pairwise evaluation, you run both system versions on the same set of inputs and directly compare each example’s outputs. This is commonly used for tasks such as summarization, where multiple outputs may be valid but differ in overall quality.
Online Evaluation
Online evaluation measures performance in production, giving you near real-time feedback on potential issues. Instead of waiting for a batch evaluation to conclude, you can detect errors or regressions as soon as they arise. This immediate visibility can be achieved through heuristic checks, LLM-based evaluators, or any custom logic you deploy alongside your live application.
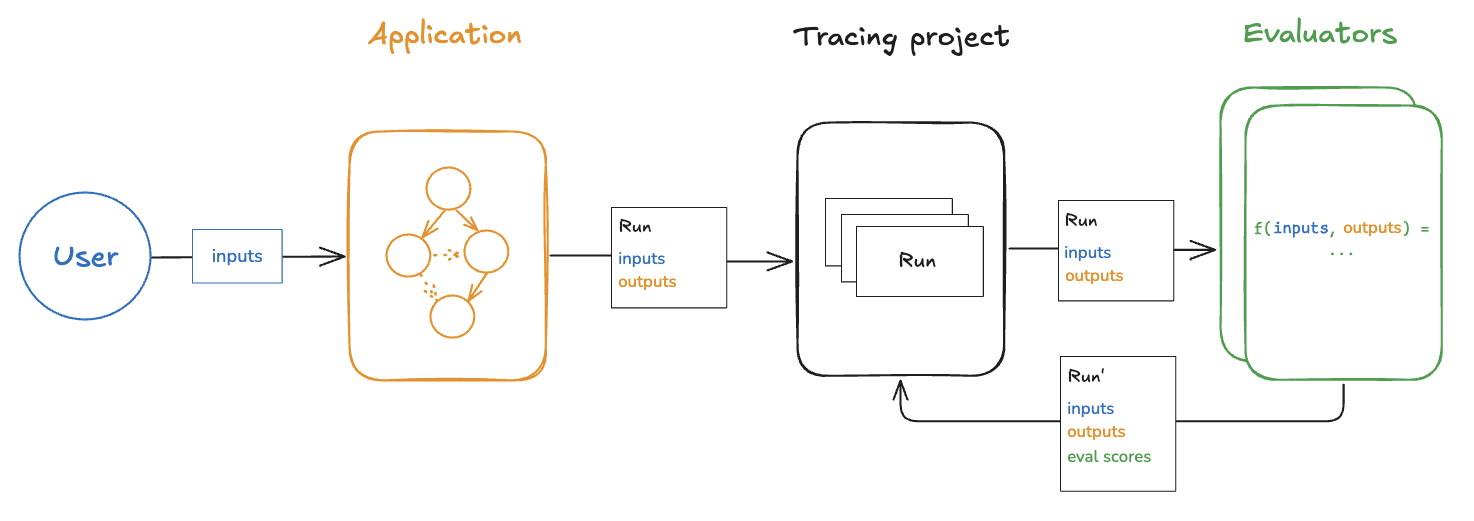
Application-Specific Techniques
LangSmith evaluations can be tailored to fit a variety of common LLM application patterns. Below are some popular scenarios and potential evaluation approaches.
Agents
Agents use an LLM to manage decisions, often with access to external tools and memory. Agents break problems into multiple steps, deciding whether to call a tool, how to parse user instructions, and how to proceed based on the results of prior steps.
You can assess agents in several ways:
- Final Response. Measure the correctness or helpfulness of the final answer alone, ignoring intermediate steps.
- Single Step. Look at each decision in isolation to catch small mistakes earlier in the process.
- Trajectory. Examine the agent’s entire chain of actions to see whether it deployed the correct tools or if a suboptimal decision early on led to overall failure.
Evaluating an Agent’s Final Response
If your main concern is whether the agent’s end answer is correct, you can evaluate it as you would any LLM output. This avoids complexity but may not show where a chain of reasoning went awry.
Evaluating a Single Step
Agents can make multiple decisions in a single run. Evaluating each step separately allows you to spot incremental errors. This approach requires storing detailed run histories for each choice or tool invocation.
Evaluating an Agent’s Trajectory
A trajectory-based approach looks at the entire flow, from the initial prompt to the final answer. This might involve comparing the agent’s chain of tool calls to a known “ideal” chain or having an LLM or human reviewer judge the agent’s reasoning. It’s the most thorough method but also the most involved to set up.
Retrieval Augmented Generation (RAG)
RAG systems fetch context or documentation from external sources to shape the LLM’s output. These are often used for Q&A applications, enterprise searches, or knowledge-based interactions.
Comprehensive details on building RAG systems can be found here:
https://github.com/langchain-ai/rag-from-scratch
Dataset
For RAG, you typically have queries (and possibly reference answers) in your dataset. With reference answers, offline evaluations can measure how accurately your final output matches the ground truth. Even without reference answers, you can still evaluate by checking whether retrieved documents are relevant and whether the system’s answer is faithful to those documents.
Evaluator
RAG evaluators commonly focus on factual correctness and faithfulness to the retrieved information. You can carry out these checks offline (with reference answers), online (in near real-time for live queries), or in pairwise comparisons (to compare different ranking or retrieval methods).
Summarization
Summarization tasks are often subjective, making it challenging to define a single “correct” output. In this context, LLM-as-judge strategies are particularly useful. By asking a language model to grade clarity, accuracy, or coverage, you can track your summarizer’s performance. Alternatively, offline pairwise comparisons can help you see which summary outperforms the other—especially if you’re testing new prompt styles or models.
Classification / Tagging
Classification tasks apply labels or tags to inputs. If you have reference labels, you can compute metrics like accuracy, precision, or recall. If not, you can still apply LLM-as-judge techniques, instructing the model to validate whether a predicted label matches labeling guidelines. Pairwise evaluation is also an option if you need to compare two classification systems.
In all these application patterns, LangSmith’s offline and online tools—and the combination of heuristics, LLM-based evaluations, human feedback, and pairwise comparisons—can help maintain and improve performance as your system evolves.